字节阿里腾讯的 AI 人才竞赛:2330 个研究者背后的共识与分歧
2025-04-09 10:23:01 晚点LatePost
大互联网平台公司都对战略业务严格保密,但AI研究是学术和工程的混合体,天然开放。大公司内的研究团队也需要密切关注最新成果,并通过顶级学术会议发布论文公开研究进展,提高影响力、吸引人才。
NeurIPS、ACL、CVPR等AI领域多数顶级学术会议上的论文投稿与评审,都通过OpenReview平台公开。
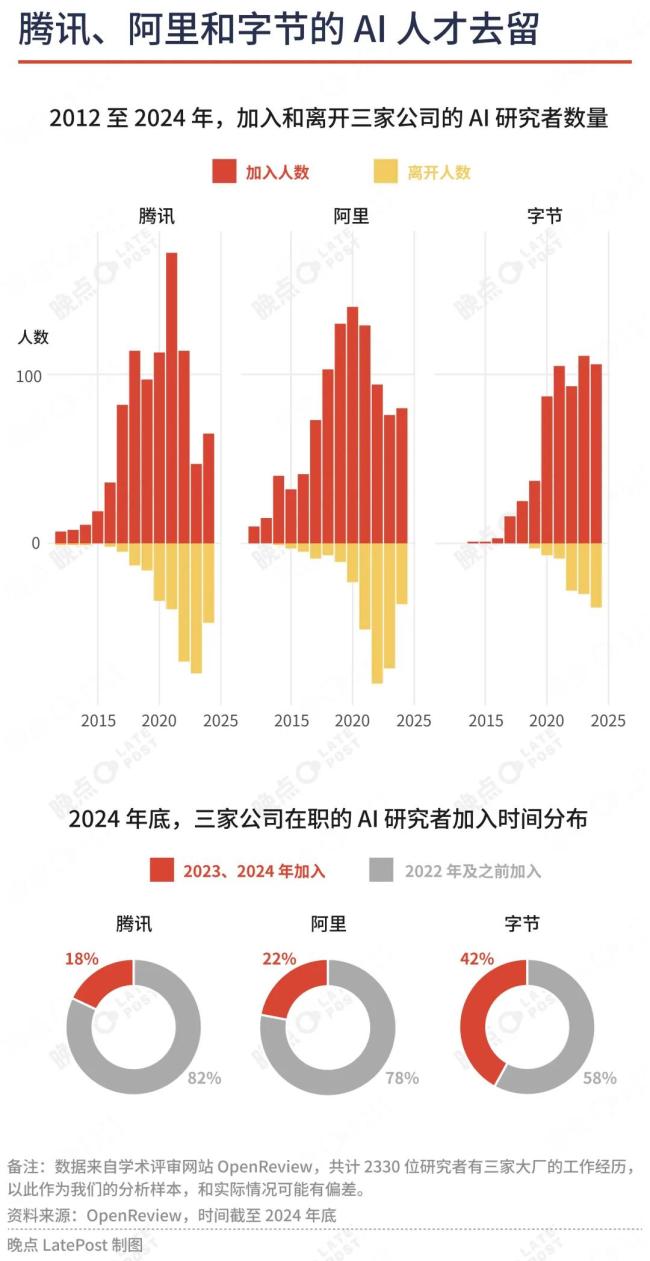
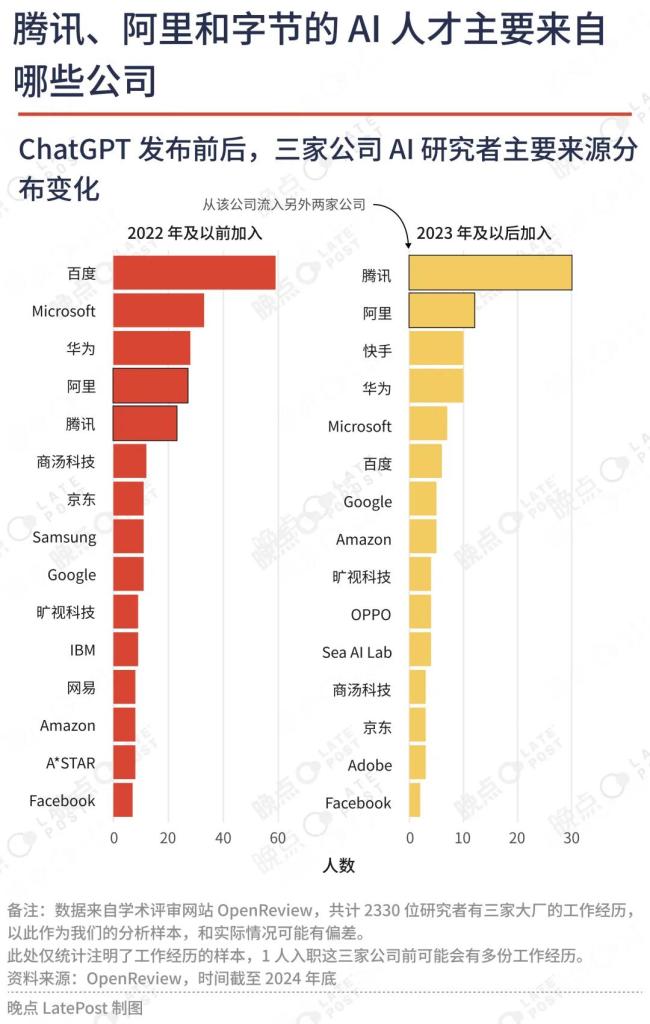
该数据库里累计有2330人以字节、阿里、腾讯员工身份发表过AI相关论文。其中有些人已经离职,有些研究与大模型无关,但这个数量依然说明AI基础研究主要是大公司的游戏,AI人才更多流向了盈利能力最可观的三家大厂。作为对比,百度有448人,其他中国互联网公司或大模型创业公司显著更少。
我们将这些数据与LinkedIn、Github等平台的信息和其他公开资料匹配,找到这些研究人员的教育背景、工作履历,并追踪了他们的流动轨迹。三家大厂招募研究者的偏好、研究人员的构成,以及研究团队架构的调整等,反映出各自在大模型浪潮中的人才投入和应对策略。
重启“博士军团”,数百万年薪抢人
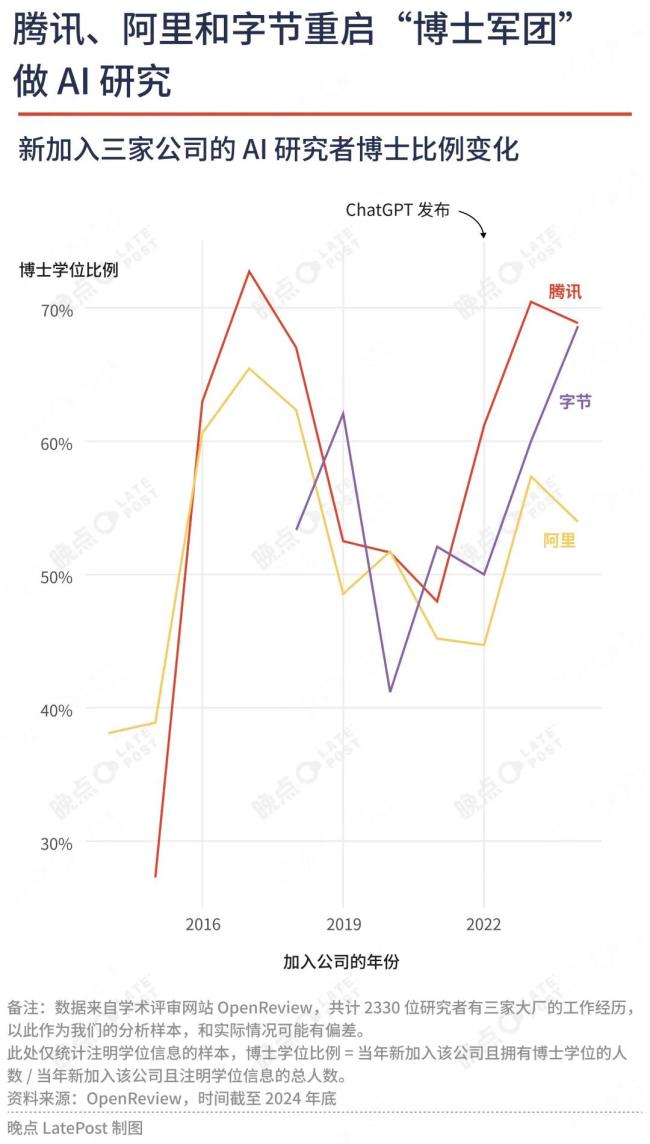
面对技术变革,大厂的惯用策略是组建“博士军团”。
上一轮计算机视觉为主的AI浪潮中,OpenReview上字节、阿里和腾讯新增的研究者,博士占比超六成,腾讯在2017年甚至超过七成。
博士军团理念最早源自硅谷,从施乐实验室到乔布斯的NeXT、互联网时代的Google都热衷于网罗习惯在学术环境下工作的博士们。
中国科技企业又比硅谷公司多了一层优势,这里的工程人才更多,也接受工作更长的时间,可以支撑企业建立大团队,沿着别人开辟的创新路径,多团队赛马、高强度研发,快速追上。
随着技术扩散和竞争焦点转向工程实践和业务层面,三家大厂研究团队博士比例明显下降。2020年到2022年,OpenReview上三家大厂新研究者中博士占比均降至50%以下,字节一度低至40%。
大模型热潮到来推动博士军团回归。OpenReview上的数据显示,过去两年,三家大厂新研究者的博士比例回升:腾讯和字节占比七成,阿里也提升到50%以上。
为了组建博士军团,三家大厂开启抢人大战,重点是即将完成学业、在大模型时代成长起来的年轻研究者。
2024 年 5 月,字节面向应届博士生发起 Top Seed 计划;一个月后,腾讯发起针对 AI 顶级人才的 “青云计划”。今年 3 月,阿里云专为在顶级学术会议发表过论文、开源过优秀项目的毕业生设置 A Star 和 Al Clouder 人才项目。
我们了解到,字节的 Top Seed 计划已经招揽 30 多名,大多数人今年入职,年薪可达数百万元人民币。
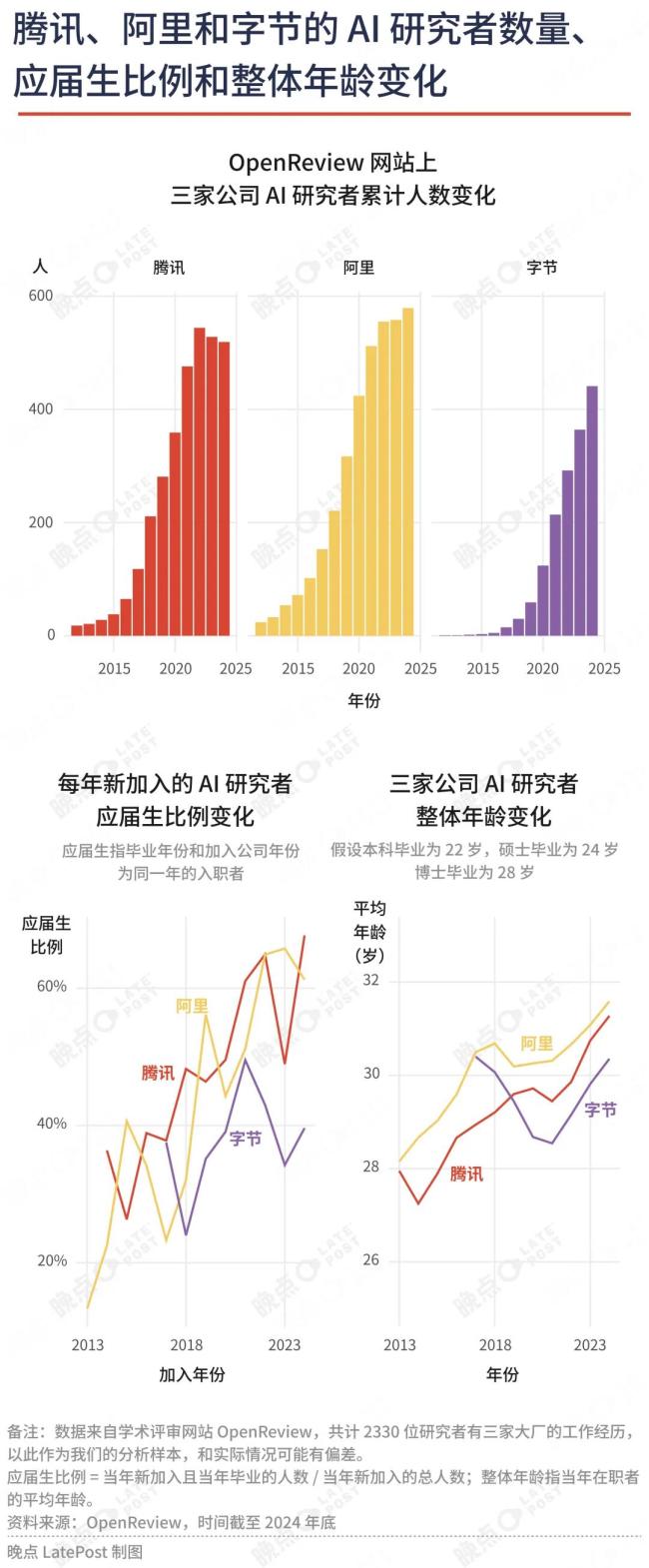
看重应届博士生,是字节对过去AI人才招聘策略的主动调整。OpenReview上,过去两年三家大厂新增的研究者,阿里的应届生占比六成;腾讯在2024年提升到七成。
而字节的应届生比例在四成左右。如果把条件设定为应届博士生,这个数字只有1/4。过去几年,字节研究团队平均年龄低于30岁,2024年又回升到30岁以上。
今年2月的字节全员会上,字节HR负责人华巍提到:一些部门最近几年偏好“招聘经验丰富的候选人”,而且“来源还很单一,集中在某几个公司”。他说,一个健康的团队,人才需要有多样性。
但多元的人才不一定必然导致创新。我们分析过DeepSeek过半研究人员的背景和工作履历:多数人不到30岁,应届生过半,大部分最高学历是本科或硕士,关键岗位负责人基本都没有博士学位,境外留过学的研究者占比不到10%。
三家大厂研究人员的学历也更漂亮。在腾讯,香港中文大学进入前六;字节的研究者中,卡内基梅隆大学毕业生数量能排第八,有留学经历的研究者占比超四成。
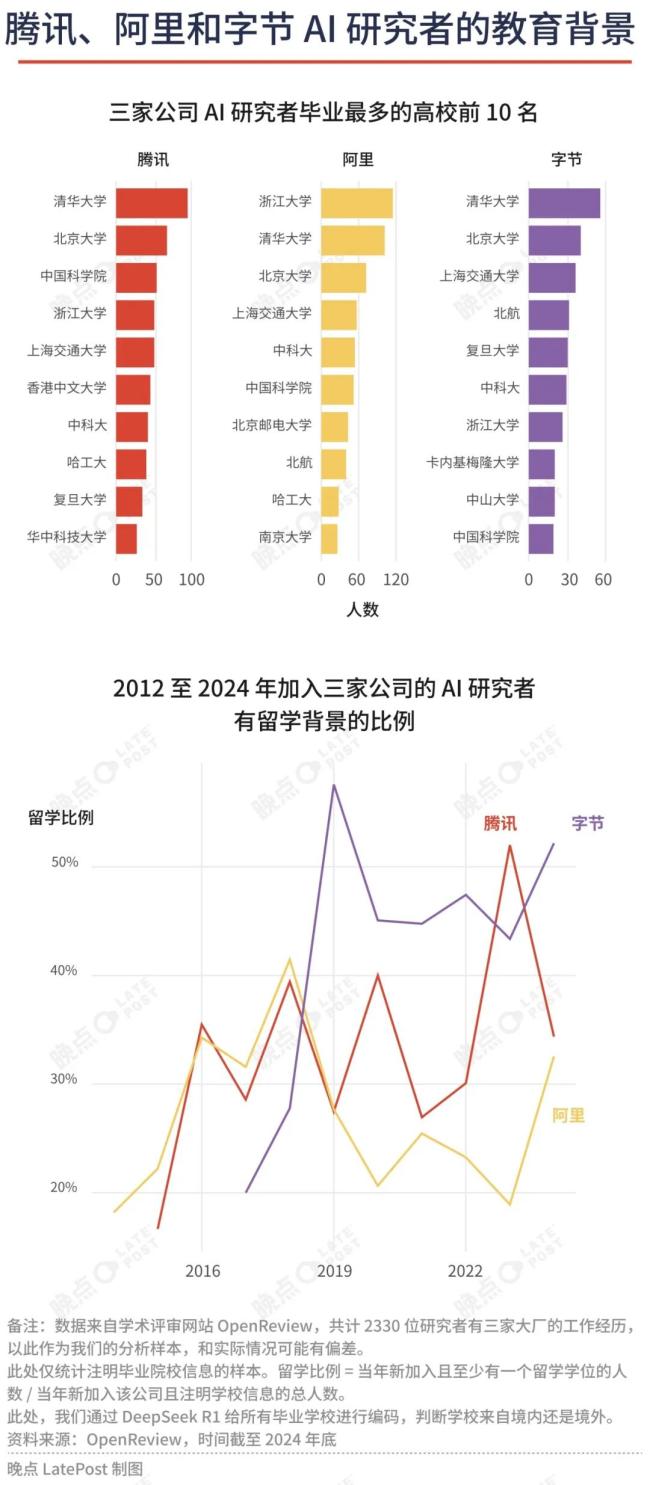
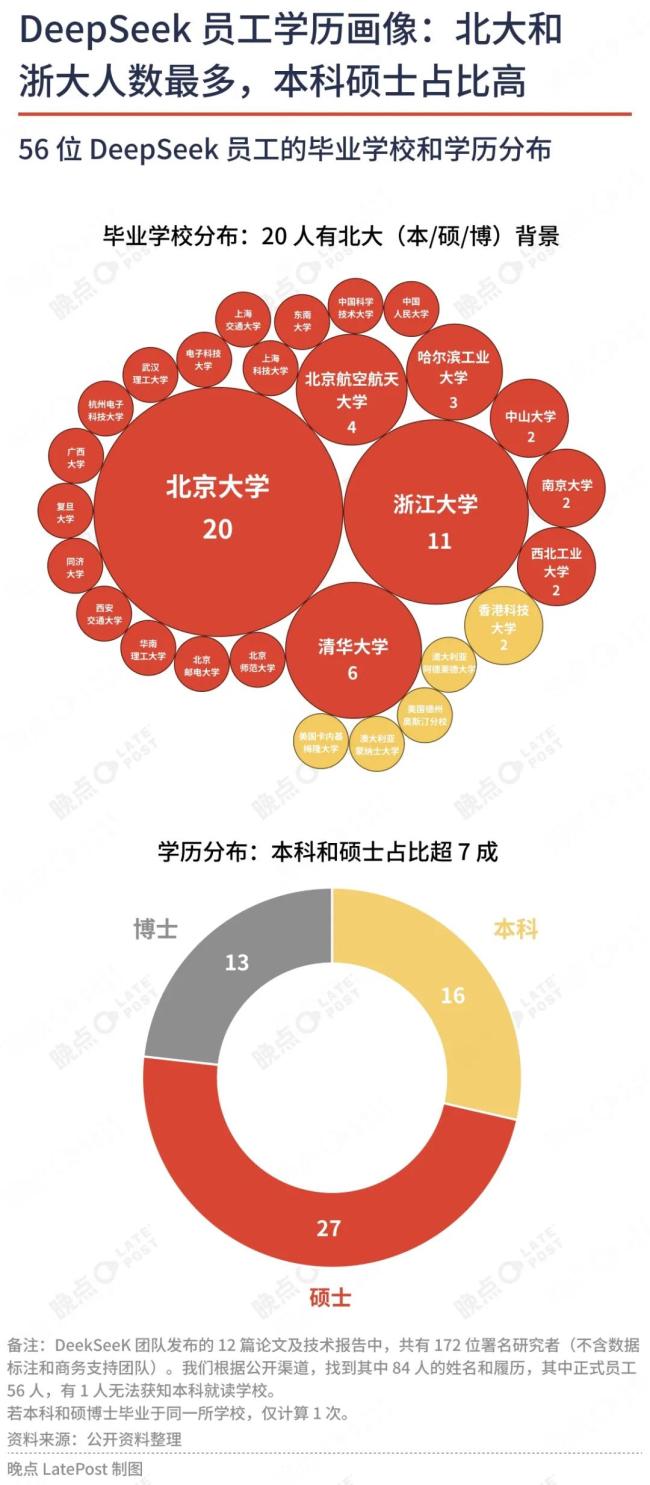
左图是三家大厂研究者的教育背景,右图是DeepSeek员工的教育背景。
一位字节人士说,吴永辉负责 Seed 基础研究团队后,常在内部强调要培养年轻人。今年 3 月,字节公布 Top Seed 研究实习生计划,最高薪资每天 2000 元,条件放宽到本科生,甚至还会邀请优秀的高中生当顾问。和 DeepSeek 一样,字节的 Seed 也允许实习生负责重要研究方向。
都组建了相对独立的研究团队,但组织形态不同
腾讯:内部竞争后组建虚拟部门,管理者多是入职十多年、甚至20年的中高管
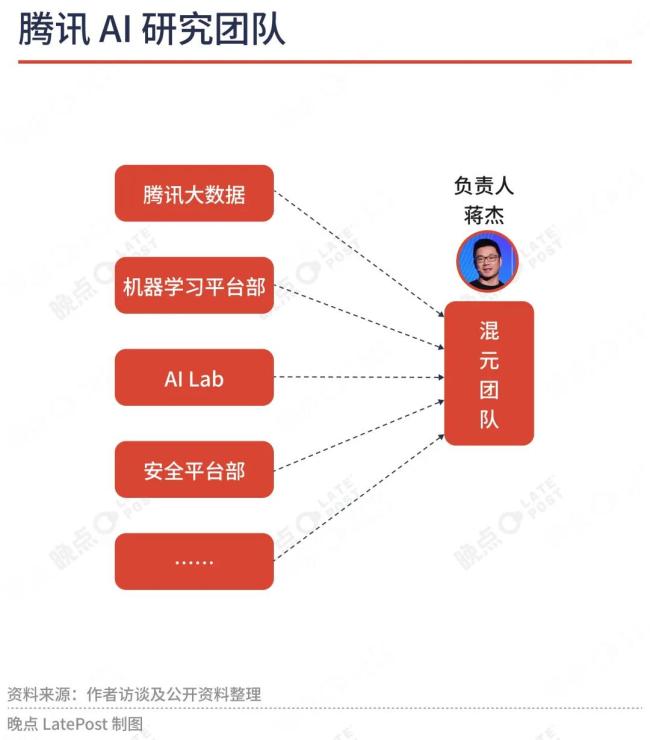
腾讯在技术工程事业群(TEG)中组建了一个跨部门的 “混元团队”,采用虚拟组织形式,横跨 TEG 的大数据、机器学习平台部、AI Lab 等多个部门。
这是腾讯内部竞争的结果。2023 年上半年,腾讯 TEG 的 AI Lab 和大数据部门分别训练大模型,虽然 AI Lab 的模型在技术上有亮点,但效果不如大数据部门, 输掉大模型研究主导权。
当前,混元团队的负责人是腾讯集团副总裁、TEG 副总裁蒋杰,他也是腾讯广告平台产品技术负责人、AI Lab 负责人。
蒋杰2012年加入腾讯,他博士毕业于北京大学,曾在阿里工作五年,参与阿里自研云计算系统中的大数据平台部分。蒋杰加入腾讯后,先后负责建设大数据平台和广告平台技术体系研发。
混元团队其他核心管理者基本都是公司资深中高管,在10年前、甚至20年前加入腾讯。
王迪,腾讯机器学习平台部总经理,负责混元大模型的训练工作。他2008年加入腾讯,曾负责腾讯搜索平台及广告相关算法,2022年起主导大模型技术在广告业务中落地。
杨勇,腾讯安全平台部负责人,负责混元大模型的数据与安全工作。他2005年加入腾讯,历任技术体系运维安全、业务安全、信息安全等核心岗位。
刘煜宏,腾讯云副总裁,负责多模态方向的研发。他2005年加入腾讯,曾负责腾讯大数据平台、机器学习平台研发及运营,一度主导大模型应用“元宝”。
康战辉,腾讯机器学习平台总监,混元大语言模型的算法研发工作。他2011年加入腾讯,从事搜索、数据挖掘与广告算法优化等研究工作。
俞栋,腾讯 AI Lab 副主任、西雅图实验室负责人,负责混元大模型中部分文本与视觉算法研发。2017 年加入腾讯,加入前在微软工作近 20 年,长期从事语音识别与自然语言理解研究。
混元团队之外,腾讯还有多个分布在不同事业群的 AI 研究团队。技术工程事业群(TEG)下有研究具身智能模型的 Robotics X 实验室,云与智慧产业事业群(CSIG)中设有以计算机视觉为主的优图实验室,平台与内容事业群(PCG)拥有 ARC Lab,而微信体系内部也长期运营着 “模式识别中心” 等。这些团队负责把混元大模型或 DeepSeek 等模型能力嵌入具体的业务和应用场景中。
阿里:达摩院和阿里云部分团队组成新部门,管理者有内部培养的应届生
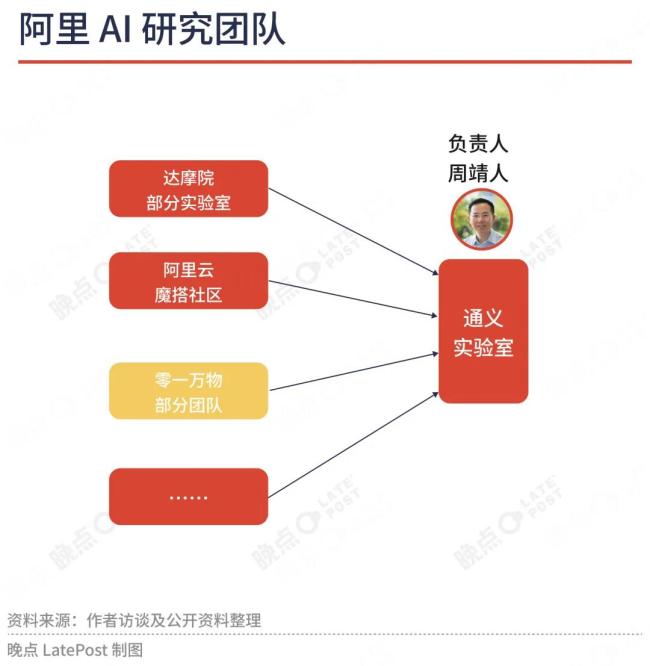
大模型浪潮到来时,阿里正在推进1+6+N变革,原本属于阿里云的AI研究机构达摩院成为N分拆出去,由曾任阿里云CEO的张建锋负责。阿里1+6+N拆分很快终止,达摩院多个研究团队,如语言技术实验室、语音实验室、XR实验室等,在阿里云重组成大模型研究部门“通义实验室”。
阿里通义实验室的负责人是阿里云CTO周靖人。周靖人2016年加入阿里云,曾在微软工作11年,做到研发合伙人。他在阿里云当过首席科学家、达摩院副院长,是阿里大模型研发的核心发起人。
通义实验室的其他负责人展现出阿里的“人才梯队”建设——既有达摩院组建时招来的技术专家,也有达摩院体系内成长起来的应届生。
黄非,通义实验室自然语言智能实验室负责人,曾在IBM、Facebook研发NLP技术,2018年加入达摩院。
薄列峰,通义实验室应用视觉实验室负责人,曾在亚马逊、京东研究用于零售的AI,2022年加入达摩院负责XR实验室。
林俊旸,通义实验室通义千问负责人,2019年北大硕士毕业后加入阿里达摩院。
刘宇,通义实验室通义万相负责人,2015年清华硕士毕业后加入阿里。
周文猛,阿里云大模型开源社区魔搭的负责人,也是通义实验室系统研发总监,2015年南京大学硕士毕业后加入阿里。
和腾讯一样,阿里云的通义实验室之外,阿里也有AI研究团队分散在其他业务部门中,比如淘天集团、智能信息事业群组、国际数字商业集团等。
这些部门大多数调用通义大模型开发AI产品,也有研发大模型实力。今年2月,新加坡管理大学终身教授、Salesforce原副总裁许主洪加入阿里担任副总裁,向智能信息事业群组负责人吴嘉汇报,其中一部分工作职责是研发多模态基础模型。
字节:独立于各业务组建新团队,管理者中有空降的技术专家
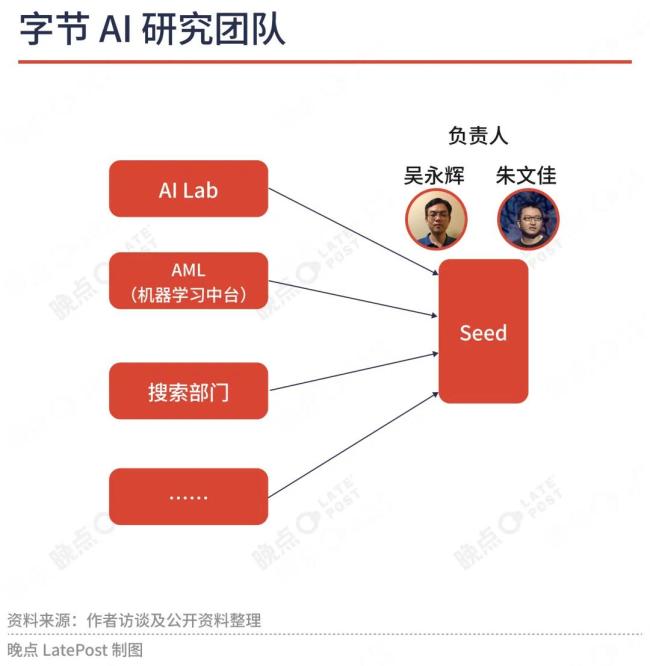
字节研发大模型较晚,包袱小目标大。他们选择从 AI Lab、AML、搜索团队等部门抽调人手组建 Seed (豆包大模型)团队。和腾讯、阿里不同,Seed 不属于字节原有业务体系内任何一个部门,负责人向 CEO 梁汝波和创始人张一鸣汇报。
当前,字节 Seed 团队有两位负责人,一是负责 “基础研究” 的吴永辉。吴永辉刚加入字节不久,他 2008 年从加州大学河滨分校拿到博士学位后就加入 Google,先后参与搜索算法、机器学习、语言模型研究,历时 17 年成长为 Google DeepMind 研究副总裁。
另一位是负责“应用研究”的朱文佳。朱文佳2015年加入字节,此前在百度研究广告推荐算法,担任过搜索部主任架构师。加入字节后,朱文佳当过今日头条CEO、TikTok产品技术负责人。2023年,Seed团队刚组建时,朱文佳是整体负责人,现在负责“贴着模型和用户需求做应用”,重点是提升基础模型的问答、创作、解题、写代码等能力。
吴永辉和朱文佳两人同时负责Seed团队,也是其管理团队的缩影:既有其他业务调来的中高层,也有大模型时代加入的技术专家。
乔木,负责豆包大模型大语言模型团队,他2014年加入字节,曾担任搜索工程部门负责人。
杨建朝,负责豆包大模型视觉多模态团队。他2018年加入字节负责视觉算法研究,曾在Adobe、Snap等公司负责研究工作。
项亮,负责豆包大模型Foundation团队。他2016年加入字节负责推荐算法研究,曾在Hulu、宜信、瓜子二手车工作。
周畅,负责豆包多模态交互与世界模型团队和部分前沿研究。他2024年加入字节,曾是阿里通义千问负责人。
黄文灏,负责Seed的部分技术项目管理规划和部分前沿研究。他2024年加入字节,曾在微软、智源研究院、零一万物工作。
Seed 团队之外, 字节还有一批 AI 研究团队,比如 AI Lab 中还有 AI for Science 和机器人小组,整体负责人李航在 2017 年从华为加入字节,现在也转向吴永辉汇报。
抖音、火山引擎、飞书等业务中,也有研究团队负责把AI用到业务和产品中,比如抖音的剪映、即梦,火山引擎的方舟模型训练平台等。
ChatGPT到来至今,腾讯的研究人员减少、阿里微增、字节大幅扩张
在上一轮AI浪潮中,字节、阿里和腾讯就组建了规模可观的研究团队。
腾讯在 2012 年、2016 年组建优图实验室和 AI Lab,微信内部还设有 “模式识别中心” 。2022 年,OpenReview 上可见的腾讯研究者有 612 人。
阿里则于2014年在硅谷成立iDST(数据科学与技术研究院),2017年在阿里云体系下组建达摩院。2022年,OpenReview上阿里的研究者有640人。
字节虽然成立较晚,在 2016 年成立 AI Lab,后又设立偏向机器学习应用的 AML(Applied Machine Learning) 团队,隶属 DATA 部门。2022 年,OpenReview 上字节的研究者有 322 人,三家大厂中最少。
这些研究者聚焦自然语言处理、计算机视觉、语音识别/合成等研究方向——这些技术是上一轮AI浪潮的重点,也是大模型研究的起点。这批研究者有迁移到大模型领域的基础,也是三家大厂研究AI的主力。
面对大模型技术突然爆发,三家大厂的应对方式截然不同。
腾讯CEO马化腾在2023年中的股东大会上说,大模型最关键的是“场景落地”,腾讯有很多场景,不急于一时。这些场景包括微信、QQ、游戏等等高频流量入口,覆盖中国网民的日常生活——只要模型成熟,想要触达用户和规模化应用,很难绕开它的产品体系。
这种判断反映在腾讯的研究团队建设上:过去两年,OpenReview上腾讯新增的AI研究者仅112位,只有2021年一年新增人数的65%。考虑到离职人员,2024年,OpenReview上腾讯的研究者减少到607人,大模型时代“新人”占比不到20%。
阿里是现阶段中国最能通过大模型直接获利的互联网平台。大多数公司不可能买上万张显卡,自己投建数据中心,只能租用云平台算力。阿里云是目前国内市占率最高的云平台,成立比腾讯云、字节火山引擎分别早4年和11年。
阿里云CTO周靖人在2023年10月曾告诉我们,阿里做大模型“不是为了做端到端的超级应用,而是给大家展示和开放能力”。
到2024年,OpenReview上阿里的研究者增长9%到696人,大模型时代新人占比刚超过20%。
字节最为激进,它希望用大模型抓住一个类似抖音的机会。过去两年,OpenReview上字节每年都新增超过上百名研究者,研究团队增长50%到480人——其中过四成是ChatGPT诞生后加入字节。
三家大厂的AI研究团队都是DeepSeek、月之暗面、MiniMax等创业公司的数倍甚至更高——国内几家大模型创业公司中,研究团队普遍在100~200人,出现在OpenReview上的研究者则少得多,而且也面临流失。
创业公司流失的研究人才,去字节的显著多过阿里和腾讯。过去一年多,字节从智谱、零一万物等创业公司吸引了不少资深研究者,比如零一万物联合创始人黄文灏、智谱核心研究员丁铭、面壁智能核心研究员秦禹嘉等人。
一位大模型创业公司的投资人向我们感慨,他曾看好的项目会是一个完美的创业故事,“如果没有字节”。当然,后来又多了DeepSeek。
阿里也变得积极。一位阿里人士说,今年初阿里云吸纳零一万物大模型预训练团队,新增60多位有经验的研究者。
大厂研究者在大厂中流动,创业是少数人的选择
2013年,百度在硅谷组建深度学习研究院,是中国最早组建团队研究AI的公司之一,把机器学习、深度学习技术用到搜索、广告等业务中。
随着竞争格局变化中失势和人才流动,百度为行业输送大量研究人才,拿到“黄埔军校”的名头。但这仅限于上一轮AI浪潮。
根据我们的分析,2023年及之后加入字节、阿里、腾讯的研究者中,有工作经历的超过30%来自三家大厂。其中腾讯占比最高,其次是阿里——两家在大模型研发上相对保守的公司,成了最大的人才供应方。
当公司战略与个人抱负不匹配时,人才外流成为必然。在我们的样本中,从腾讯离开的研究者,多数就职于内部大模型研发竞争中失势的 AI Lab。
2024年中,阿里通义千问负责人周畅离职,是中国大模型行业人才流动的标志事件。他2017年北大博士毕业后加入阿里,是达摩院体系内培养起来的应届生。
“通义做得很好,为何要用这么多钱和算力支持外面的团队?”一些阿里人士曾向我们表达共同的困惑。
周畅一度考虑创业,但他只见了少数投资机构,数位试图接触周畅的投资人告诉我们,当时“根本约不上”“发消息不回”。
最后他选择了字节。一位接近周畅的人士告诉我们,字节高层一对一和周畅聊过,表达了追求顶尖AI技术的决心。
周畅加入字节也是中国大厂研究人才流动的典型——创业或加入一家创业公司,只是少数人的选择。
我们的分析样本显示,从字节、阿里、腾讯离开的研究者,超过四成去了体量较大的公司(字节、阿里、腾讯、华为、蚂蚁、美团等),其次是高校或研究机构,占比1/4。
可能是因为竞业协议或工作地点影响,我们还发现16%的离职者选择加入海外公司,比如亚马逊、Meta;最后才是创业或加入一家创业公司,占比只有不到14%。
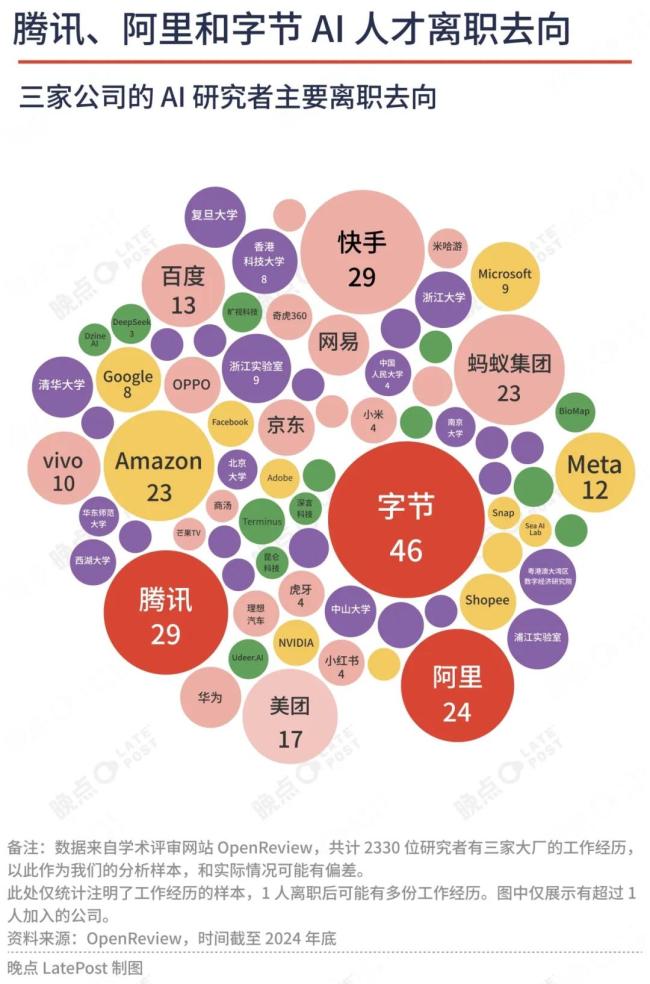
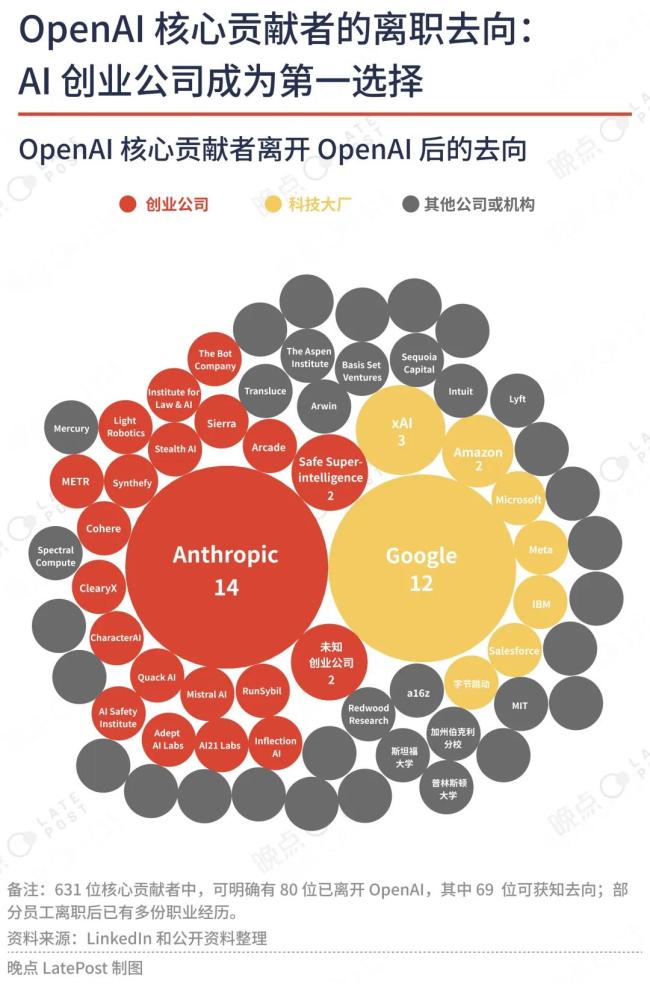
左图是三家大厂离职研究者去向,右图是OpenAI离职研究者去向。
去年11月,我们分析过OpenAI研究人才流动情况,Google、Meta等大厂和Stripe、Dropbox等独角兽公司为OpenAI贡献了最多的人才,OpenAI的离职者创业或加入创业公司人占比过半,形成一个完整的AI创业生态。
“全世界就一个硅谷。”一位AI投资人说,创业不只需要创始人有能力、有承担高风险的自觉,还要有适合创业的环境。
DeepSeek刷新竞赛,大厂加码基础研究
三家大厂高层都把大模型视为长期竞争,但普遍选择了务实的研究策略:沿着行业内验证过的方法,尽可能快地训练出“第一梯队”的模型,看重模型对产品或具体业务的助益。
字节Seed团队的大语言模型部门考核指标,曾大多都是让模型变得更实用,比如提高代码生成能力、建设模型评测平台、提供可以供内外部调用和精调的多个模型版本等等。
腾讯和阿里的考核指标类似。不过腾讯更偏重模型用到产品中的表现,而阿里将其作为一个云服务产品,看重大模型的“影响力”。
这种策略确实取得了成效。字节用一年多时间就在国内的大模型行业占据上风,阿里云也成功用大模型推动收入增长,只有腾讯表现平淡。
DeepSeek的崛起直接挑战了大厂的研发节奏:一个专注基础研究的小团队,做出了行业领先的大模型DeepSeek-R1,用最简单的产品形态和开源,越过了大厂的业务体系。
腾讯迅速在产品中接入DeepSeek-R1,发起应用冲刺。而字节和阿里把DeepSeek视为挑战,更加重视基础研究。
字节CEO梁汝波在2月的全员会上说,“行业内有DeepSeek这样优秀的团队,可以让我们保持警醒”,并把探索智能上限列为研究团队的核心目标之一。
同样在2月,阿里CEO、阿里云CEO吴泳铭在财报会上说,阿里“必须追求AGI(通用人工智能)”,要追求突破模型智能边界。
DeepSeek崛起的关键之一是,他们给研究者提供了发挥能力的简单环境。如果聪明的年轻人每天都要面对不懂技术的中层管理者,或者少有试错机会,不断被要求在会议上证明自己的想法可行,就很难有什么创造力。
“创新需要尽可能少地干预和管理。”梁文峰此前接受36氪访谈说,他们通常不给研究者前置分工,而是“自然分工”。
一个典型的DeepSeek工作流程是:研究者遇到问题“会拉人讨论”;有想法可以调用训练集群的卡试错,无需审批;当想法显示出潜力,管理层会自上而下地调配更多资源。
大厂过去组建AI研究团队时也想建立这样的研究环境,但又难以接受低产出的不确定性。一位大厂研究院负责人曾告诉我们,在大公司如果研究员提出一个前瞻性、学术价值高的问题,“它的价值首先要打个问号”。
多年来,腾讯、阿里、字节的研究者都在两种导向间来回摇摆:要么背上业务指标生存,要么离职回高校或研究机构。
现在大厂又想在内部提供宽松的研究环境。年初,字节组建虚拟组织 Seed Edge,专注研发下一代大模型技术,项目有突破时才做绩效评估,而不是其他业务的半年考核一次。
3月,阿里云发起名为“T项目”的虚拟组织,也要研发下一代大模型技术,向包括研究与产品在内的员工开放,只要评审通过,就能获得资源支持。阿里云内部将其称为“可能改变未来的战役”。
不过大厂的大模型主力研究团队仍沿着旧节奏推进,还是要迅速做出能力达到行业“第一梯队”的大模型,供内部产品和外部客户调用,扩大影响力,抢占市场份额。
竞争没有就此停下。引入DeepSeek-R1的腾讯,也没有减少投入,混元团队还加快了模型迭代速度。
大厂不缺资源,也不缺场景,它们渴望独占胜利。不过它们想赢得这场战役,最大障碍也许并不在外部,而是它们自身的组织惯性。