DeepSeek Inside:彻底的技术开放,成就的商业奇观
2025-02-18 10:57:59 晚点LatePost
中国正在经历自己的“ChatGPT时刻”。过去三周,DeepSeek的官方应用永远被人流挤到瘫痪边缘,与此同时数百家公司正式接入了它研发的大模型。MiniMax、阶跃星辰等与它有竞争关系的AI创业公司接入了,元宝、文心一言这样的大公司AI产品也接入了。
高潮是上周末,微信,这个几乎从不追赶任何潮流的国民级应用也在搜索页面接入了DeepSeek-R1。根据我们了解,腾讯最高层在近期曾与DeepSeek创始人梁文锋见面。除了微信以外,QQ浏览器、QQ音乐、腾讯文档等腾讯的十几个产品也都接入DeepSeek。
一个没花一分钱营销的技术公司实现了 “DeepSeek Inside” 的品牌奇迹。
这个奇迹只能诞生在中国:
01互联网渗透最彻底的人口,每天6小时泡在数字世界里,抖音、小红书、微信、微博等平台接力将DeepSeek送到每个人眼前。
02先在全球技术社区引发热议,后在国内发酵,完美贴合在全球AI竞赛激发的情绪。
03春节假期造就社交裂变温床,被子女“安利”的长辈们点开小鲸鱼图标,完成AI在中国的首次全民级破圈。
做到这一切,DeepSeek用的是从业者、投资者此前不敢想的方式:持续开源自己最好的模型。
ChatGPT震撼世界后,OpenAI选择保密、引入微软投资,竭力接入尽可能多的流量。两年后,面对类似的流量海啸,DeepSeek仍中立、开放,没拿投资,不与任何一个大厂深度合作。这让各公司在接入DeepSeek模型时都少了一份决策压力。
“上善若水,水利万物而不争。” 开源的 “不争”,让底层云平台,中间层 AI Infra 厂商,再到直接面向用户的消费级 AI 应用都加入这场 “接流量” 大赛,也在全行业做了一次 AI 普及教育。
48小时定增幅的平台算力竞速
算力云平台是DeepSeek流量盛宴中最直接的受益者。
1月28日,春节假期第一天,DeepSeek的官方API调用接口已接近瘫痪。
大模型推理引擎云平台硅基流动创始人袁进辉在朋友圈复盘:1 个月前,DeepSeek 创始人梁文峰就问过他,要不要在硅基流动平台上部署 DeepSeek 12 月底发的 V3,他算账后发现,如要保证用户体验,得用 80 张 H800(英伟达的一款 GPU),每个月要花五、六百万元,觉得风险太大就放弃了。
“现在DeepSeek这么火,决策失误......欲哭无泪。”袁进辉说。
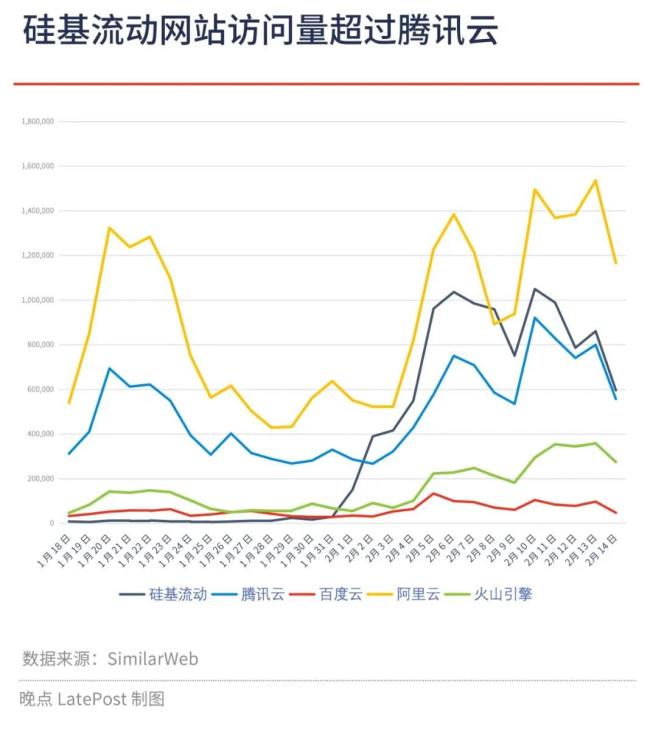
3 天后的 2 月 1 日,假期紧急加班的硅基流动与华为合作,成为中国率先接入 DeepSeek V3 和 R1 模型的云服务公司,接到前所未有的流量。
据SimilarWeb数据,硅基流动网站访问量之后10天增长30多倍突破到100万,超过腾讯云,甚至一度超过行业第一阿里云。
紧接着,中国头部的公有云平台,腾讯云、阿里云、百度云、火山引擎,同样赶在春节期间上线DeepSeek模型的API服务,甚至拿出更低的价格。但因为晚了48小时,它们的增长幅度就比硅基流动差一大截。
紧随其后的是电信、移动、联通等运营商的云平台以及国家超算平台。春节假期刚结束,它们就上线DeepSeek模型,推动其往城市服务、大型国企中扩散。
尽管有充足的准备,云厂商们还是低估了DeepSeek的流量。
2月1日上线DeepSeek模型当天,硅基流动的DeepSeek模型API服务就和DeepSeek官方一样,陷入瘫痪状态。
“我原本以为我们能接住。”袁进辉说,他们只能限流,然后去找更多算力卡支持汹涌而来的客户需求。大量用户流向字节、阿里、腾讯的平台。
但巨头也没能平稳接住。字节火山引擎在2月4日上线DeepSeek新模型,API服务也一度陷入瘫痪。
用于本地部署大模型的硬件跟着上涨。一名算力服务商人士告诉我们,现在一块 GeForce RTX 4090(英伟达的游戏显卡,可用于大模型推理)的价格已经从去年中的 1.4 万一块涨到 1.9 万。到 2 月 14 日,英伟达市值已回到 3.4 万亿美元,此前下跌的股价完全修复。
也有人的判断是,中小云平台不该急于跳入这场API接入竞赛。
开源 AI 框架 Caffe 的主要作者之一,推理引擎云平台 Lepton.ai 创始人贾扬清认为,虽然 DeepSeek 是很牛的模型,但跟风用它做推理服务很难做出差异化:AI Infra 不能烧钱,因为都是标品。而今天的公共 API 比速度、比稳定性,意义不大,比的就是钞能力。小厂没必要跟着大厂一起烧钱。
“所以我的朋友圈现在就像加持良治,别人在打使徒,他在种西瓜。”贾扬清在社交媒体上说。
生态奇观:DeepSeek被嵌入竞争对手,带动竞品增长
1 月 27 日至今,DeepSeek 的应用一直在中国苹果 App Store 免费总榜的下载量第一。其扩散曲线快过 ChatGPT,也快过抖音,一个是 AI 时代增长最快的产品,一个是移动互联网时代增长最快的产品。
而且只靠DeepSeek“一个盆”完全承接不住大海般的对AI的好奇与试用。DeepSeek的定位也使它无意响应汹涌而来的消费级用户需求。现在当用户使用DeepSeek官方产品,短时间内只能问一个问题,再问就是“服务器繁忙”。
据SimilarWeb数据,DeepSeek的网页版产品,访问量在1月28日达到高峰的3786万,半月后已下跌超过一半至1683万。同期,微信中讨论DeepSeek的热度(微信指数)增长了27%。
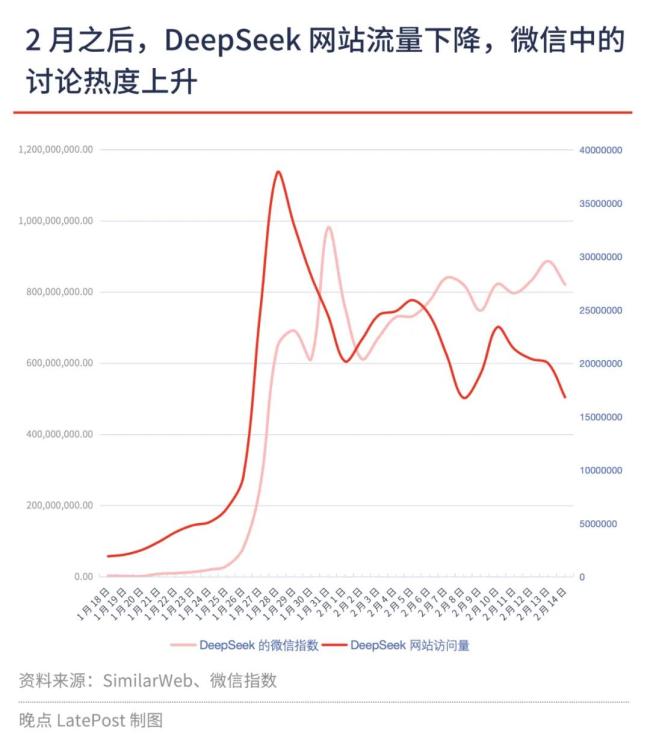
这带来需求外溢的机会。据SimilarWeb数据,豆包网页版春节后的高峰访问量比春节假期前的高峰期高了27%,Kimi是54%。
2月8日,百度悄然更新核心的大模型应用文小言,称接入DeepSeek-R1优化拍照解题功能,之后又宣布将把DeepSeek接入搜索中。
差不多同一时间,阿里系的钉钉和大模型产品通义灵码也都接入 R1,钉钉甚至还在应用商店中改了名字,加上 “DeepSeek R1 大模型已接入”。而钉钉的对手,字节系的飞书也很快宣布在多维表格功能中引入 R1。
腾讯,这家两年前在自研大模型上略慢一筹的巨头,此刻表现出前所未有的进攻性。2月13日,腾讯宣布大模型应用元宝接入R1。据SimilarWeb,元宝网页版当天流量上涨250%。
2天后,腾讯再抛“炸弹”——每天超过10亿人在用的微信,开始灰度测试在AI搜索功能中接入R1模型。
这是一个在微信中隐藏较深的功能:用户打开微信后,需要先点搜索框,再点下方可能会出现的AI搜索,然后选R1模型,才能对话。即使如此,该功能也很快就被冲击到崩溃状态,无法正常使用。
市值超过千亿美元的中国大型科技公司中,还有拼多多没在旗下产品中接入DeepSeek的模型。它自2023年就独立于AI竞争之外,没对外发布过任何大模型或产品进展。
在此期间,凭借自研大模型获得高额融资的部分创业公司,如MiniMax、阶跃星辰,也都在旗下个人应用中引入了DeepSeek。
这种状况与两年前大模型行业的主流观点截然相反。那时大模型在中国掀起热潮,大多数创业者信奉“双轮驱动”,同时做大模型和商业化应用,相互绑定。
核心产品接不接,一号位的选择题
据我们了解,把DeepSeek接入核心产品的互联网巨头,基本都是一号位做的最终决策。此前他们基本都只用自研大模型。
一位知情人士说,腾讯最高管理层与DeepSeek梁文锋近期见过。在大公司中,腾讯目前对DeepSeek的接入范围最广。除元宝、微信外,腾讯接入DeepSeek的产品还有腾讯文档、QQ浏览器、QQ音乐等,到现在已有至少14个。
多位百度人士告诉我们,百度要在搜索场景中用R1、要在4月1日将文心一言免费、6月30日把模型开源等一改常态的决策,是CEO李彦宏最终拍板。
与此同时,对增加新功能新技术远比微信更积极的字节至今没有在主力个人AI产品豆包上接入DeepSeek。
字节 1 月发布大模型豆包 Pro 1.5 时,在官方技术博客中写道,字节用推荐、搜索和广告领域积累的 AB Test 经验,开发了基于用户反馈的模型训练流程,可以 “通过用户数据飞轮持续提升模型的实际使用体验”。字节认为用户与自身模型迭代之间有正反馈。
关于产品和应用是否应该分开,巨头有不同的看法,这可以从它们的组织结构看出来。
腾讯和阿里近期都拆开了原本放在一起的大模型研发团队与应用开发团队。去年底,阿里把通义应用从阿里云转到智能信息事业群,由该事业群总裁吴嘉负责,模型研发留在阿里云旗下的通义实验室。1月中旬,腾讯将大模型应用元宝从研发大模型的事业群TEG转到CSIG,交给腾讯会议的负责人吴祖榕。大模型研发团队混元仍然留在TEG。
而在字节,模型研发和产品的组织依然紧密——字节 AI Flow 大部门下,有做豆包等 AI 产品的 Flow,也有做模型的 Seed,还有做工程优化的 Stone。
创业阵营中,MiniMax创始人闫俊杰今年1月中旬曾告诉我们,过去AI行业的一个误区就是,“认为用户越多,模型能力提升越快”,其实二者没有直接关系,应该把模型和技术分开看:“技术就是要不断提升上限;而产品的目的不是让模型变好,它就是一个商业化产品,真正需要思考的是怎么更好满足用户。”
MiniMax 在其 MiniMax Chat 产品和 to B 的开放平台上都已接入了 DeepSeek 模型。
“新一代模型不在牌桌上,基于上一代模型的产品也没意义。”MiniMax、Liblib.ai等AI公司的早期投资人,明势资本合伙人夏令的观察是,AI产品和模型当前是“松耦合”,如果决定继续追基座模型和推理模型,就不要被产品制约,从商业化考虑,该接别人的模型就接,“短中期看,产品本身不是模型和公司的关键胜负手了”。
头部创业公司中,与DeepSeek官方产品形态相似的Kimi(月之暗面)暂未接入DeepSeek。OpenAI近期发表的一篇关于思维链的论文里提到了两个来自中国的模型,一个是DeepSeek-R1,一个就是Kimi-k1.5。一位接近月之暗面人士称,“都是推理模型,又都有比肩o1的表现,这可能是月之暗面还未接入DeepSeek的主要考量。”
不论大公司还是创业公司,都一边接入DeepSeek,一边在迅速迭代自己的模型。就在今天,腾讯在接入DeepSeek-R1的元宝中也上线了自研推理模型混元T1,称“用户可以选不同的模型,解决复杂问题”。这更像互联网公司都熟悉的赛马。
彻底的开放,成就最大的商业奇迹
“一家非美国公司正在延续 OpenAI 的初心——真正开放、前沿的研究,赋能所有人。”DeepSeek 开源 R1 模型后,英伟达 AI 科学家吉姆·范(Jim Fan)说,DeepSeek 不仅开源一系列模型,还公开训练秘诀。
同一时间,Meta 首席科学家杨立昆(Yann LeCun)也说,外界不要只关注中美 AI 竞争,DeepSeek 更重要的价值是 “开源对闭源的胜利”。
DeepSeek之前,中美都有大模型公司开源模型,其中Meta的Llama系列模型迅速扩散,让Google一位资深研究员声称,OpenAI、Google等模型闭源公司都没有护城河。但最后填上护城河的是DeepSeek。
DeepSeek比肩第一梯队闭源模型的性能和较低的训练和部署成本,是它的内核与爆发基础。
更深入的开源则给它带来 “魔法加成”:从第一个自研大模型 DeepSeek LLM 至今,它一直开源自己最好的模型,而且一直用自由度最高的开源协议之一 “MIT 开源协议”,允许开发者自由下载使用、修改发布,用于商业用途也不需要付费。相比一批开源转闭源的公司,如 Mistral 等,DeepSeek 到目前为止保持一贯的开源动作。
与Meta、阿里相比,DeepSeek更中立:它没有像OpenAI(与微软)、Anthropic(和亚马逊)那样,与某家大公司绑定,也没有引入任何投资方。
在各类公司决定是否接入DeepSeek的决策中,这是一个与模型性能、开放程度同等重要的因素。
开源之路在之前对中国创业公司来说几乎不是一个选择。
“DeepSeek说明这条路(开源)能走通。如果在以前,一个拿几亿美金融资的公司说自己要开源,估计投资人会吐血。”一位投资人说。据我们了解,至少有两家此前闭源的大模型公司接下来可能会开源自研的领先模型。
DeepSeek不是一家典型的创业公司,它做大模型的路径不是从0开始,以融资撬动未来回报,而是基于幻方成立9年的积累。在相对充足的资金、算力环境下,实践大部分人不看好发展路径,这是它到现在为止极致开源、开放的基础。
梁文锋对Open的AI有多执着?一个小故事是,2023下半年,硅基流动(SiliconFlow)筹备期间,梁文锋想要投资,但说“如果LLM推理引擎不开源就没兴趣了”。硅基流动创始人袁进辉后来分享,当时他并没有想明白开源的商业模式,就没拿这笔钱。
一位头部大模型公司人士最近看到这个故事感慨说:“梁文锋真是太疯了!”